
- 从文本中创建词向量bayes.py
1 | #!usr/bin/python |
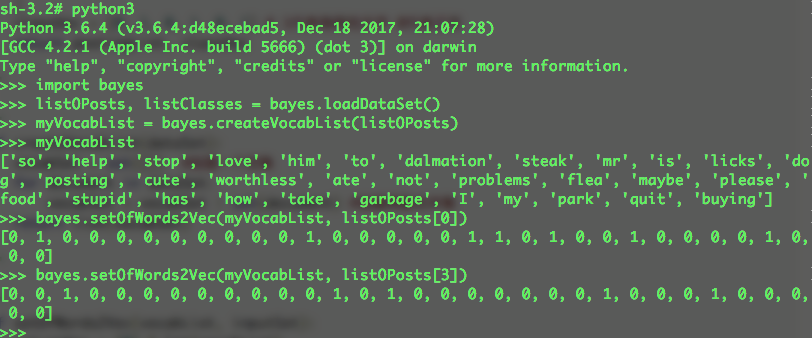
- 朴素贝叶斯训练函数
1 | #朴素贝叶斯训练函数 |
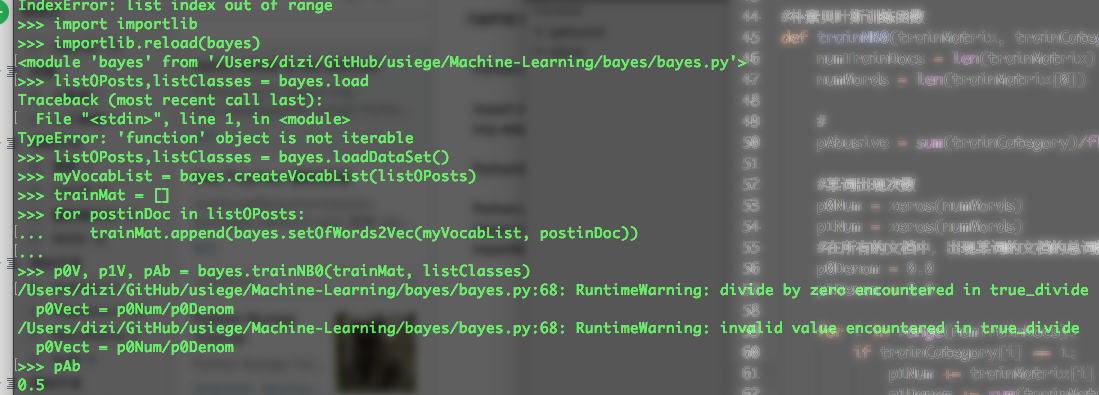
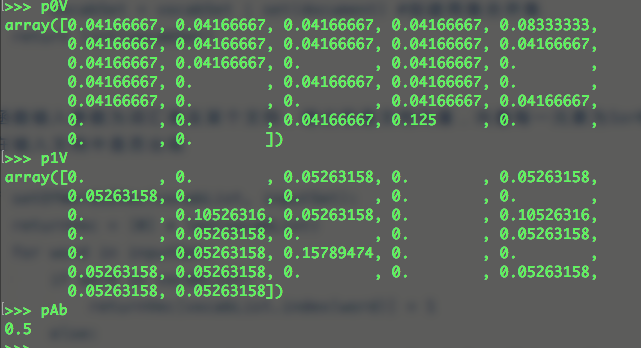
- 修改分类器
- Problem1:计算多个概率的乘积以获得文档属于某个类别概率,如果其中有一个概率值为0,那最后乘积也为0;为降低这种影响,可以将所有词出现初始化为1,并将分母初始化为2
1 | p0Num = ones(numWords); |
- Problem2: 下溢出,太多很小的数相乘会造成下溢出,解决办法是取自然对数,把乘法转换成加法,通过求对数避免下溢出或者浮点数舍入导致错误
1 | p1Vect = log(p1Num/p1Denom) |
- 分类器编写
1 | #构建朴素贝叶斯分类函数 |
通过训练器分类得出结果:
- 文档词袋模型
1 | #文档词袋模型 |